


Файл robots.txt содержит информацию для поисковых ботов, которые сканируют и индексируют ваш сайт. В нём вы можете прописать правила и инструкции, с помощью которых укажете, например, какие страницы нужно скрыть из поиска, какие не надо проверять и т.д.

Пример файла robots.txt
Что позволяют делать инструкции в этом файле?
- Запрещать сканирование страниц или директорий сайта.
- Запрещать сканирование частей содержимого страницы (например, картинки, CSS-файлы, JS-файлы и т.д.).
- Совмещать запреты и разрешения на сканирование (когда можно сканировать страницу, но не картинки на ней).
- Настраивать запреты и разрешения для разных поисковых ботов.
- Настраивать url-ссылку на главное зеркало.
- Управлять частотой сканирования страниц поисковыми роботами.
- Настраивать url-ссылку файлов Sitemap.
Отметим сразу, что даже самый грамотно прописанный файл robots.txt не является для поисковых ботов строгим правилом. Имеющиеся в нём инструкции носят лишь рекомендательный характер, но чаще всего боты им следуют.
Написать самому или скачать готовый?
Файл robots.txt можно полностью составить с нуля или взять готовый и отредактировать его при необходимости. Однако вы должны представлять, как устроен этот файл, какие директивы в нём используются. Неправильно составленный файл может стать причиной проблем: например, ваш сайт не будет индексироваться, или в сеть утекут приватные данные.
Онлайн-генераторы
Если вы решили создать robots.txt с помощью генератора, то нужно максимально внимательно отнестись к этому процессу. Во-первых, под каждую CMS (Bitrix24, WordPress, Tilda и т.д.) создаются собственные файлы. Они могут отличаться по структуре или количеству используемых директив.
Также в сети можно найти готовые шаблоны robots.txt, в которых прописаны основные инструкции. Вы можете использовать их, доработав под свой сайт.
В любом случае обязательно ознакомьтесь с правилами подготовки в справке Яндекса и Центре Google Поиска.
Есть несколько генераторов, которыми вы можете воспользоваться:
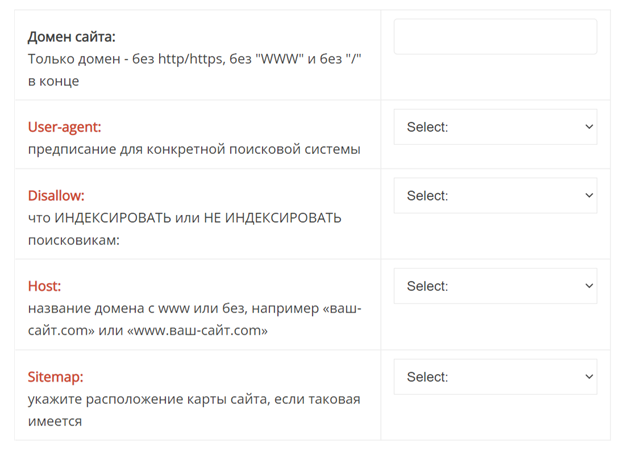
На скриншоте видно, что в конструкторе с помощью нескольких кнопок вы можете выбрать, какие запрещать или разрешать для индексации.
На некоторых генераторах вы можете выбрать дефолтные настройки под определённые CMS. После создания нужно обязательно проверить полученный файл.
Создание вручную
Написать файл robots.txt можно в любом текстовом редакторе. Главное, сохранить его с расширением .txt (то есть в формате текстового файла). В начале работы чётко определите, какие именно страницы вы хотите скрыть от сканирования или индексации.
Директивы и символы
При подготовке файла нужно использовать определённые директивы.
- User-agent. С неё начинается любой robots.txt. Она определяет, для каких именно ботов прописаны последующие инструкции. Например, User-agent: Googlebot относится к ботам Google. User-agent: Yandex обращается ко всем ботам Яндекс. При этом вы можете указать директиву User-agent: YandexNews, которая пропишет инструкции только для ботов от Яндекс.Новости.
- Disallow. Эта директива запрещает индексацию страниц сайта. Рекомендуется закрывать корзины и страницы с заказами, поисковые формы, административную панель, всплывающие формы для заполнения, рекламные баннеры и т.д.
- Allow. Эта директива разрешает боту сканировать и индексировать страницы сайта.
- Sitemap. Она отображает карту сайта. Если вы сообщите её роботу, то вы ускорите индексацию сайта.
- Crawl-delay. Директива задаёт временный интервал между сканированиями страниц. Это позволяет снизить нагрузку на ваш сервер.
- Clean-param. Она используется ботами Яндекса и помогает верно определить страницу для индексации, если её URL содержит динамические параметры (идентификаторы реферов, сессий и т.д.), которые не влияют на содержимое.
Кроме директив, при написании robots.txt используются символы.
/ — разделяет URL-префиксы в ссылках, чтобы определить степень вложения страниц. Например, запрет в виде Disallow: /catalog/ запрещает к индексации все вложенные в неё страницы, но разрешает индексировать верхнюю. А вот Disallow: /catalog запретит для индексации только эту страницу. Важно обращать внимание на правильные написания директив и символов.
* — этот символ используется в директивах Disallow и Allow и означает любую последовательность символов. При этом всегда неявно приписывается к концу каждого URL-префикса. Например, Disallow: /*catalog/ запрещает индексировать все страницы, URL которых содержит /catalog/. Но — при этом разрешена индексация страницы с адресом /catalog (разница в наличии слеша).
$ — символ отменяет неявное использование * в окончаниях URL-префиксов. Например, директива Disallow : /*catalog/$ запрещает индексацию страниц, которые заканчиваются на catalog/. Однако оставляет открытыми /catalog или /necatalog. При этом $ не отменяет действие прописанного символа * в окончаниях URL. То есть директивы Disallow: /catalog/* и Disallow: /catalog/*$ будут работать одинаково — запрещать к индексации все URL-адреса, начинающиеся с /catalog.
Требования к файлу
Есть общие требования к robots.txt, которые предъявляют к нему поисковые системы.
- Формат — .txt
- Имя — robots (строго в нижнем регистре)
- Размер — не более 500 кб
- При запросе файла, сервер должен возвращать код 200 ОК
- Файл должен находиться по адресу домен/robots.txt
- Кодировка — UTF-8, включающая коды символов ASCII
- Раскладка — только eng (кириллица запрещена)
Если не выполнены требования по имени, расширению или местонахождению файла, то поисковые боты его просто не найдут. В таком случае, весь сайт будет считать открытым для индексирования.
Яндекс и Google
При создании и редактировании robots.txt вы можете прописать правила для ботов Яндекс и Google. А можете, например, создать общие правила для всех (для этого в начале файла просто пишем директиву User-agent:* и всё). Однако лучше всего прописать правила для обоих ПС.
Почему стоит указывать User-agent: Googlebot и User-agent: Yandex? Поисковые системы позитивнее реагируют на такие директивы. Кроме того, вы можете управлять индексацией страниц в разных поисковых системах: например, контент, который будет сканироваться ботами Google, но пропускаться Яндексом.
Что нужно запрещать к индексации в robots.txt?
Есть несколько запретов, которые рекомендованы для использования с ботами любых поисковых систем.
-
- Дубли страниц. Переходя по каждой url-ссылке, бот должен видеть уникальный контент. Дубли нужно скрывать с помощью масок.
- Страницы с неуникальным контентом. Их нужно скрывать сразу, чтобы они не повлияли на ранжирование всего сайта в поисковой системе.
- Страницы, применяемые при работе сценариев. Это любые страницы, на которых есть сообщения в духе «Спасибо за покупку!», «Благодарим за отзыв!» и т.д.
- Файлы движка сайта. Это шаблоны, темы, базы, панели администраторов и другие подобные файлы.
- Ненужные пользователям страницы и разделы. Обязательно закрывайте от ботов пустые страницы, результаты поиска, бесполезный для пользователей контент и т.д.
- Профили пользователей и информацию о них
Как проверить созданный файл?
После создания robot.txt его нужно переместить в корневой каталог сайта. Чтобы облегчить проверку и найти все возможные ошибки, можно использовать сервисы поисковых систем:
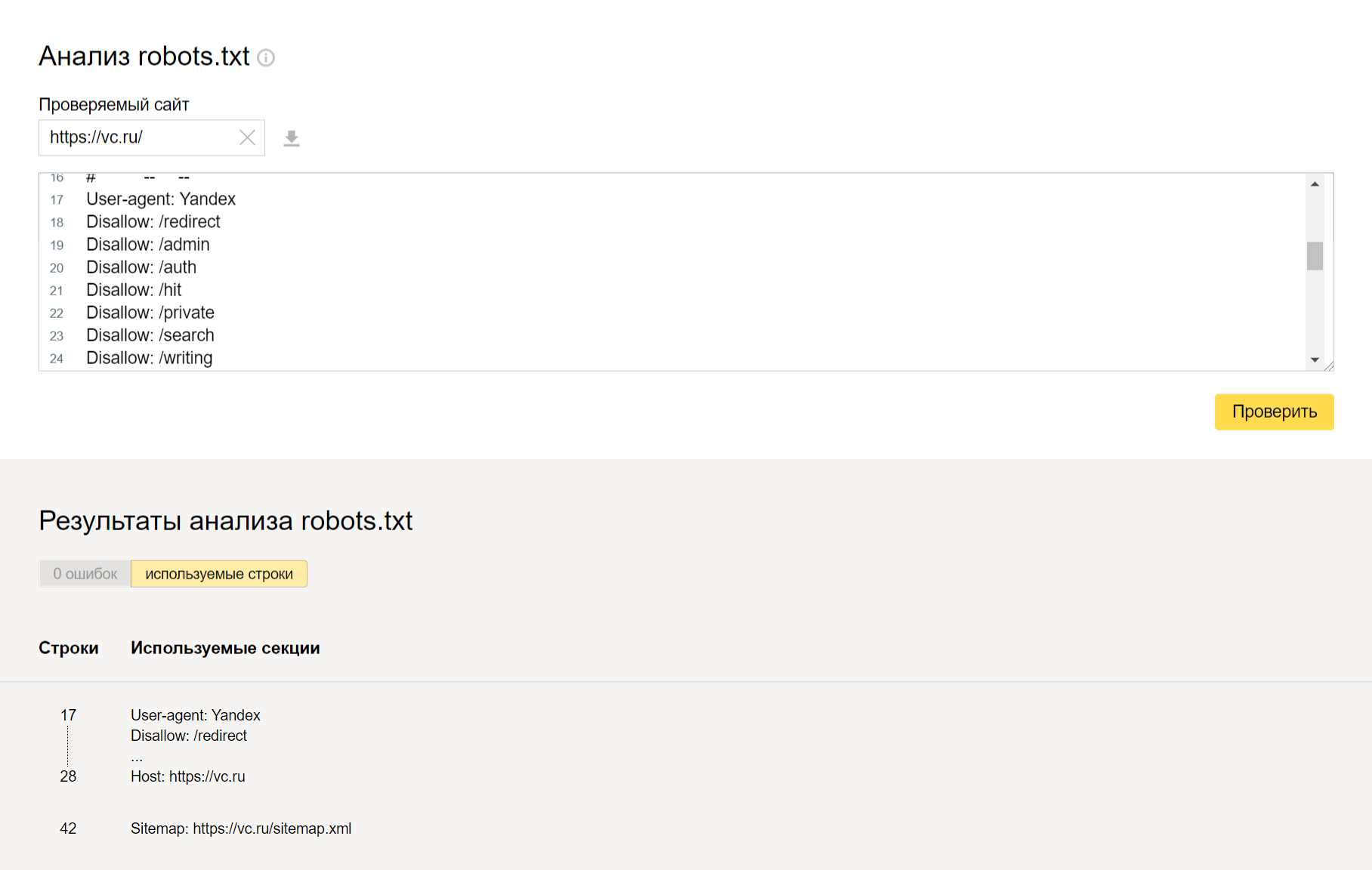
После проверки вы получите сообщения о всех допущенных ошибках и проблемах. Если вы исправляете файл прямо на сервисе, то потом нужно обновить robot.txt на хостинге вашего сайта вручную или через административную панель CMS.
Выводы
Файл robots.txt — это один из главных инструментов для SEO-продвижения. Поэтому для успешной индексации и ранжирования сайта создавать и настраивать его надо в обязательном порядке. Правильно оптимизированный файл поможет сэкономить краулинговый бюджет, снизит нагрузку на сайт со стороны поисковых машин, которым не надо будет обходить технические страницы, а также уберёт из выдачи ненужную или приватную информацию. В итоге вы будете повышать свои позиции в поисковой выдаче.
Как работают алгоритмы магазинов прил, почему одни продукты оказывают в топе, а другие никак до него не доберутся? Виноваты ли в этом плохие отзывы или агрессивный дизайн, маленький бюджет на продвижение или плохо собранная семантика? Разбираемся в «дьявольских» деталях ASO-продвижения с ребятами из команды iRent!






