


В рамках конкурса авторских статей на ZorbasMedia и розыгрыша денежных призов представляем вам нашего следующего участника — Lukos рассказал о результатах парсинга арбитражных СМИ.
Всем привет. Меня зовут Lukos, я автор колонки про мобильные приложения, спикер ZM CONF 3, и человек, который устал каждый раз представляться, вспоминая какие-то регалии.
На днях я наткнулся на статью, где человек пытался подсчитать, сколько зарабатывают арбитражные медиа. После нее меня заинтересовало, о чем конкретно они пишут. Понятное дело, что про арбитраж трафика, но хотелось бы понимать конкретные темы. Поэтому я решил провести свое маленькое исследование, а именно проанализировать контент ZorbasMedia и нескольких конкурентов. Если неинтересны технические подробности и весь процесс, то вся основная информация будет содержаться в графиках и изображениях.
Приступим.
Шаг первый
Мне необходимо было добыть все статьи, которые есть на сайте
В теории, можно было бы запросить у редакции материалы в текстовом формате, но это заняло бы много времени, да и не факт, что у них хранятся исходники за столько лет редакции.
Самое банальное, что пришло в голову — это написать бота, который будет парсить весь сайт. Примерно представляя весь объем работы, который мне предстояло сделать, уже думал все послать.
Я вспомнил, что у большинства сайтов есть sitemap, созданный для поисковых ботов. Мне это сыграло на руку. Все ссылки на статьи хранятся в определенной директории. Все что мне оставалось сделать — это написать скрипт, который спарсит все эти ссылки. Дело 5 минут.
Далее, передо мной стояла задача вычленить весь текст статьи из каждой ссылки. Библиотека Beautifulsoup для Python с этим прекрасно справилась.
Все что мне оставалось, сохранить каждую статью в отдельный текстовый файл на своем компьютере. Файлов получилось 708, именно столько статей было написано редакцией ZorbasMedia за все время существования русскоязычной версии сайта.
Шаг второй
Из каждой статьи необходимо вычленить ключевые слова
Опять проблема. Большинство готовых решений заточены под англоязычный текст, а с кириллицей они работают плохо. Составлять свой bag of words заняло бы у меня примерно вечность.
По сути, передо мной стояла задача извлечения именованных сущностей из неструктурированных текстов. Немного погуглив, выбор пал на 3 библиотеки:
- pullenti
- ispras от ИСПРАН
- natasha
Отталкиваясь от документации, было написано 3 функции под каждую библиотеку, дабы сравнить функционал и выбрать лучшую.
Прогнав несколько текстов через каждую функцию, было выяснено, что pullenti извлекает меньше всего сущностей. Python версия этой библиотеки давно не обновлялась, поэтому эта SDK почти сразу отошла в сторону.
Сравнивая ispras и natasha, оказалось, что они показывают примерно одни и те же результаты. Но natasha опережала по количеству сущностей и скорости работы, и несмотря на то, что на нее ушло много времени, чтобы разобраться с документацией, я, как настоящий джентльмен, все-таки выбрал Наташу.
Далее был написан простой цикл, который пробегался по каждому файлу и добавлял именованные сущности в общий массив. В рамках одного текста удалялись все дубликаты, дабы какая-нибудь одна статья, в которой часто повторяется одно и тоже ключевое слово, не могла повлиять на общий результат. Также стоит отметить, что ввиду того, что наша сфера имеет много специфичной терминологии, я не делал нормирования и не приводил слова к одному значению. Т.е, к примеру, ФБ, Facebook и фейсбук или iGaming и Гемблинг — это разные сущности и подсчет для них идет отдельно.
Шаг третий
Визуализация
Не вижу особого смысла описывать, каким образом проходила визуализация. Т.к там нет ничего особенного, обычное облако текста и построение графиков с помощью numpy.
Вот такое облако текста получилось для ZorbasMedia:

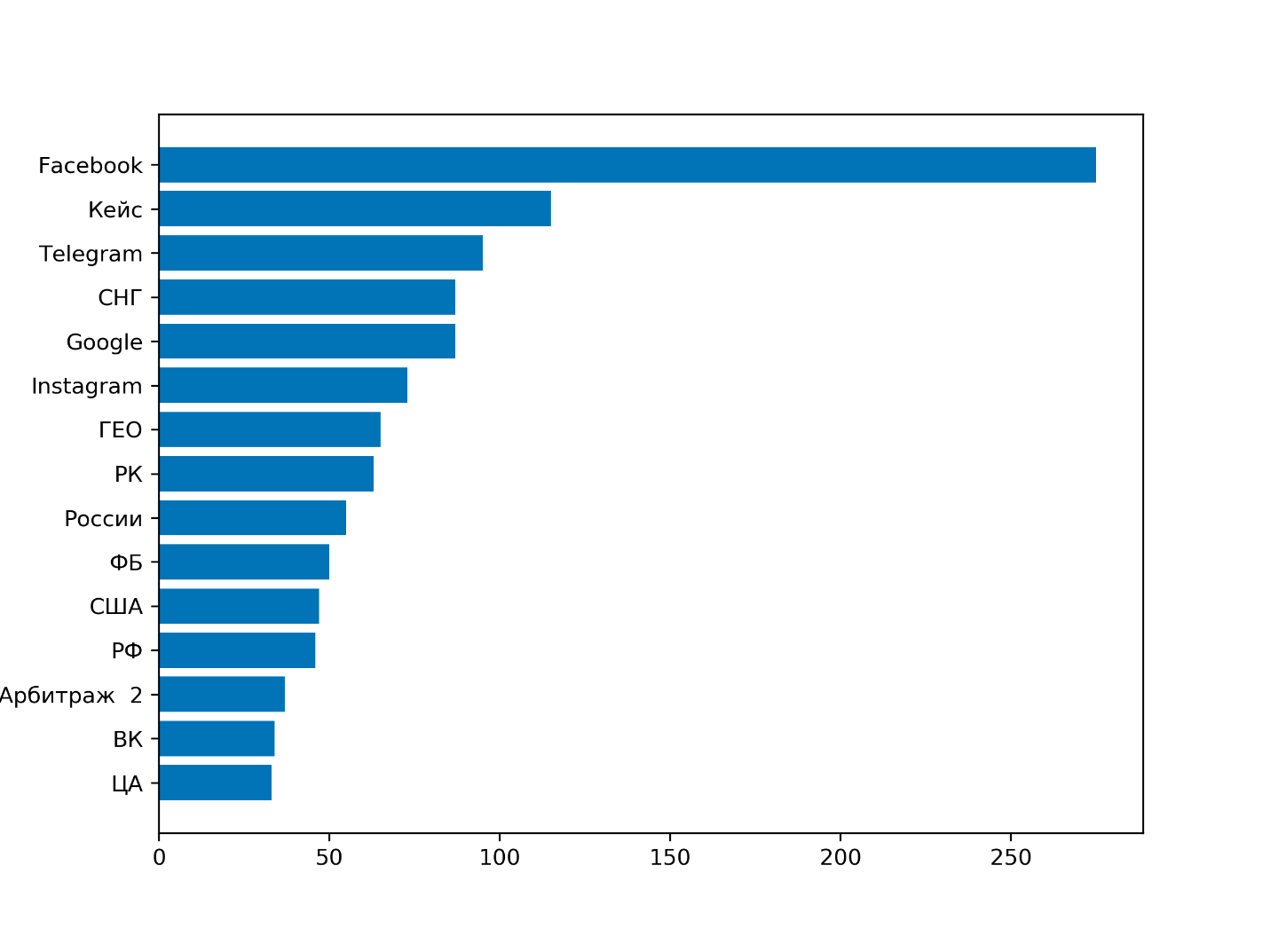
А вот это ТОП тем, про которые чаще всего пишут:

Шаг четвертый
Далее мне нужно было проанализировать контент конкурентов
Я сразу столкнулся с проблемой, что у них структура sitemap отличалась от того, что было у ZorbasMedia, поэтому я вернулся на первый шаг и подправил парсер.
Второй шаг ничем не отличался, поэтому просто скажу, что у одного конкурента размещено более 1000 статей, а у второго 574.
Конкурент 1
Облако текста:
Список самых упоминаемых тем:
Конкурент 2
Облако текста:

Список самых упоминаемых тем:
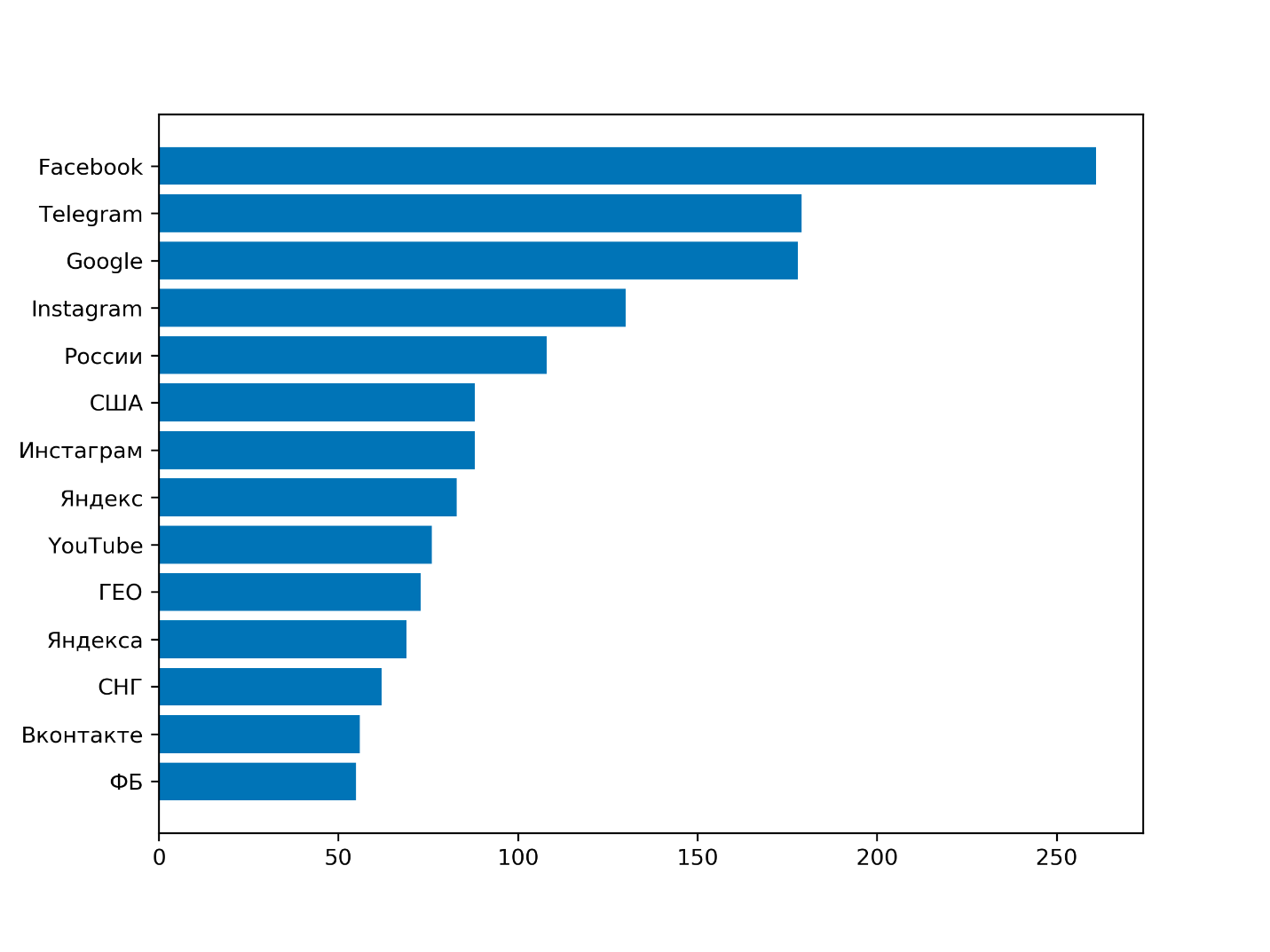
Заключение
На основе одних из самых популярных арбитражных медиа, можно сделать вывод, что самая востребованная тема среди арбитражников — это Фейсбук. Видимо, вопрос банов и залива из фб волнует большинство, а контент, который затрагивает эту проблему, собирает самые большие охваты. Интересный инсайт, как для мелких арбитражных ресурсов, так и для тематических блогов.
Как работают алгоритмы магазинов прил, почему одни продукты оказывают в топе, а другие никак до него не доберутся? Виноваты ли в этом плохие отзывы или агрессивный дизайн, маленький бюджет на продвижение или плохо собранная семантика? Разбираемся в «дьявольских» деталях ASO-продвижения с ребятами из команды iRent!






